1. 중복순열
1~n의 숫자 중 m개를 중복순열로 선택하기
n개의 노드를 가진 트리를 m레벨 만큼 내려가며 1에서 n사이의 숫자를 중복하여 선택한다
import sys
input=sys.stdin.readline #input 속도 개선/ 문자열 읽을 시 input().rstrip()으로 개행문자 제거필수
#중복순열
def dfs(lev):
global cnt
if lev==m:
print(res)
cnt+=1
else:
for i in range(1,n+1): #1~n까지 m번 돌면서 하나씩 선택
res[lev]=i
dfs(lev+1)
if __name__=="__main__":
n,m = map(int,input().split()) #n개 중 m개 중복순열 > n개의 노드 트리 m개 레벨 생성
res=[0]*m
cnt=0
dfs(0)
print(cnt) #중복순열의 개수
2. 순열
순열은 중복순열과 로직이 거의 똑같다.
단, dfs를 태울때 중복으로 선택하지 않도록 체크해주면 된다.
import sys
input=sys.stdin.readline #input 속도 개선/ 문자열 읽을 시 input().rstrip()으로 개행문자 제거필수
#순열
def dfs(lev):
global cnt
if lev==m:
print(res)
cnt+=1
else:
for i in range(1,n+1): #1~n까지 m번 돌면서 하나씩 선택
if(ch[i]==0): #선택하지 않은것만
res[lev]=i #선택
ch[i]=1 #체크
dfs(lev+1)
ch[i]=0
if __name__=="__main__":
n,m = map(int,input().split()) #n개의 노드 트리 m개 레벨 생성
res=[0]*m
ch=[0]*(n+1) #중복 제외처리 체크배열
cnt=0
dfs(0)
print(cnt) #순열의 개수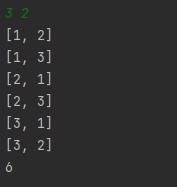
3. 조합
조합은 1~n의 숫자들 중 m개를 선택한 부분집합끼리도 중복이 없어야 한다. [2,4]=[4,2]
n개의 숫자중 하나씩 택할때마다 다음 노드는 무조건 앞에서 선택한 것보다 큰 수를 선택하도록 한다. (중복방지)
import sys
input=sys.stdin.readline #input 속도 개선/ 문자열 읽을 시 input().rstrip()으로 개행문자 제거필수
#조합
def dfs(lev,node):
global cnt
if lev==m:
print(res)
cnt+=1
else:
for i in range(node,n+1): #node~n까지 m번 돌면서 하나씩 선택
res[lev]=i
dfs(lev+1, i+1) #트리 가지에 +1 (중요)
if __name__=="__main__":
n,m = map(int,input().split()) #n개의 노드 트리 m개 레벨 생성
res=[0]*m
cnt=0
dfs(0,1)
print(cnt) #조합의 개수
참고
반응형
'Program Language > Python' 카테고리의 다른 글
| [Python 알고리즘] 부분집합 (DFS) (0) | 2023.02.01 |
|---|---|
| [Python 문법] list 리스트 메소드 (0) | 2022.03.09 |
| [Python 문법] 정렬 sorted() 옵션 (0) | 2022.02.17 |
| [Python 문법] 유용한 파이썬 딕셔너리 모듈 - defaultdict, Counter (0) | 2022.02.08 |
| [Python 문법] defaultdict : 딕셔너리 리스트처럼 사용하기 (append, remove) (2) | 2021.05.09 |