DOM (Document Object Model)
- 문서 객체 모델 : 트리 형태의 프로그래밍 도구 (위>아래로 노드 쌓임)
- HTML, XML을 프로그래밍적으로 다루기 위한 도구 (웹 페이지 문서를 표현, 저장, 조작함)
- 문서의 논리적 구조, 문서가 접근되고 조작되는 법을 정의
- 구조화된 노드(태그)와 속성, 기능(JS 함수)을 가진 객체로 표현
JS (JavaScript)
웹 페이지를 위한 프로그래밍 언어 (JIT 컴파일 PL)
DOM으로 HTML을 웹이 애플리케이션처럼 동작하는데 도움을 줌
비 브라우저 환경에서도 사용 (Node.js)
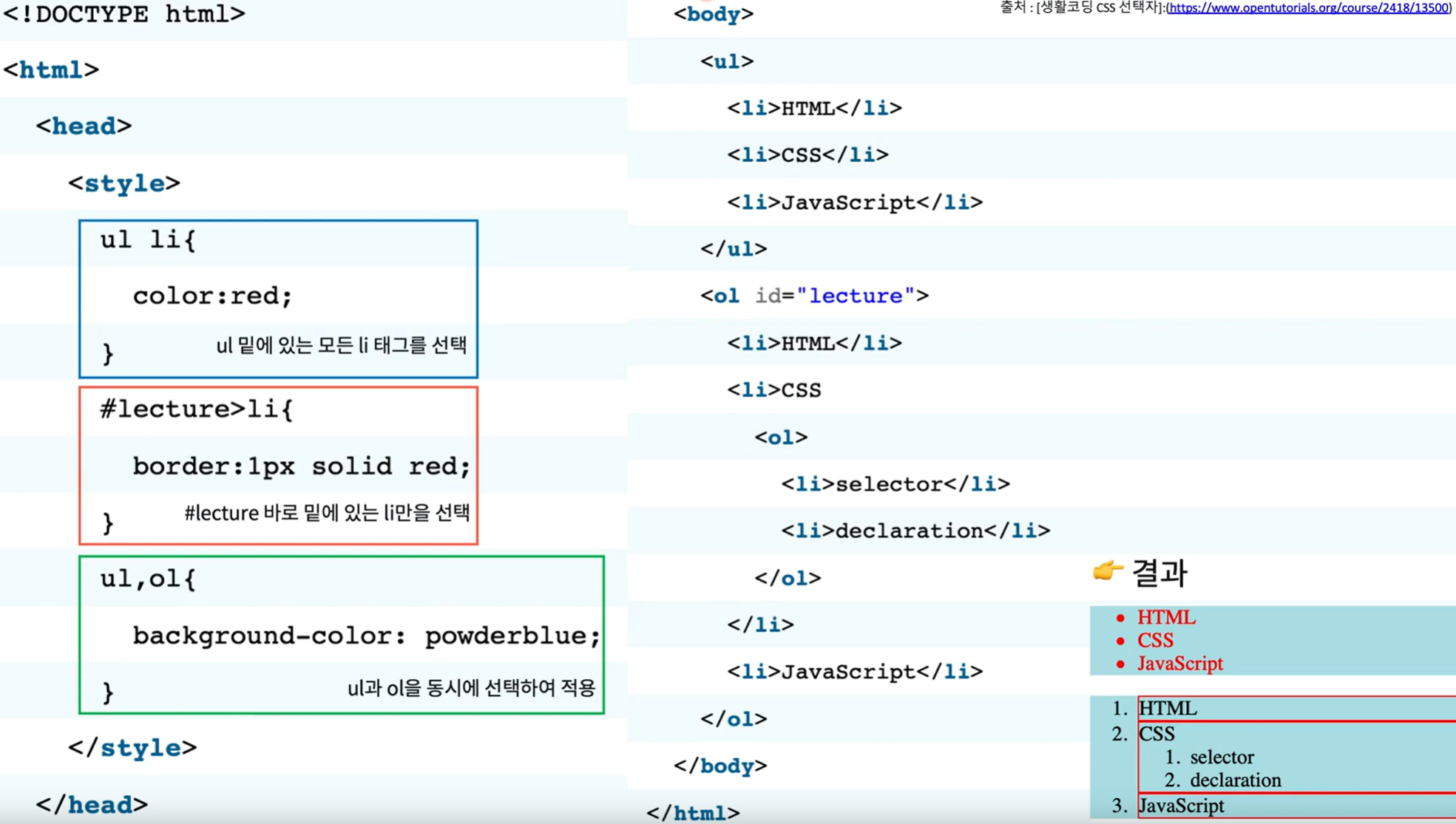
자바스크립트로 DOM 선택하기
- document.querySelector('선택자') : 선택자의 정보를 통해 요소를 집어내는 함수
- document.createElement('html요소') : 자바스크립트로 HTML 요소를 만드는 함수
- document.body.appendChild() : body 요소 내부에 새로운 요소를 넣는 함수
var element=
document.querySelector('Head');
console.log(element.nodeName); //Head<script> //HTML 요소를 불러온 뒤에 아래 함수 실행됨
window.onload=function(){ //h1 태그 가진 html 요소 생성
var heading=document.createElement('h1')
heading.innerText='Hello, world'
document.body.appendChild(heading)
}
</script>
Reference
실용적인 웹 프로그래밍 - 인프런 | 학습 페이지
지식을 나누면 반드시 나에게 돌아옵니다. 인프런을 통해 나의 지식에 가치를 부여하세요....
www.inflearn.com
반응형
'Web > 실습' 카테고리의 다른 글
| 웹 서비스 다뤄보기 (1) - HTML, CSS (0) | 2021.05.12 |
|---|---|
| 크롤링 (2)-환경설정 : pip 라이브러리, requests, BeautifulSoup (0) | 2021.05.10 |
| 크롤링 (1)-개념 및 방식 (0) | 2021.05.03 |