문제
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
1. 실행 대기 큐(Queue)에서 대기중인 프로세스 하나를 꺼냅니다.
2. 큐에 대기중인 프로세스 중 우선순위가 더 높은 프로세스가 있다면 방금 꺼낸 프로세스를 다시 큐에 넣습니다.
3. 만약 그런 프로세스가 없다면 방금 꺼낸 프로세스를 실행합니다.
3.1 한 번 실행한 프로세스는 다시 큐에 넣지 않고 그대로 종료됩니다.
예를 들어 프로세스 4개 [A, B, C, D]가 순서대로 실행 대기 큐에 들어있고,
우선순위가 [2, 1, 3, 2]라면 [C, D, A, B] 순으로 실행하게 됩니다.

풀이
from collections import deque
def solution(priorities, location):
answer = 0
dq=deque()
#0
for i,v in enumerate(priorities):
dq.append((i,v))
priorities.sort(reverse=True)
while True:
#1
if dq[0][0]==location and dq[0][1]==priorities[0]:
return answer+1
#2
elif dq[0][1]!=priorities[0]:
top=dq.popleft()
dq.append(top)
#3
else:
a=dq.popleft()
del priorities[0]
answer+=1
return answer0. 우선순위 배열을 (인덱스, 값) 형식의 deque로 생성 (이후 우선순위 배열은 내림차순 정렬)
1. 대기 큐 첫 원소가 찾으려는 location이면서 max 우선순위이면 출력차례를 return
2. max 우선순위가 아닌 원소는 다시 대기큐 맨 뒤로 이동
3. max 우선순위이지만 찾는 location 원소가 아닌경우 pop, 우선순위 배열에서도 max 우선순위 삭제, 출력순+1
반응형
'Problem Solving > Programmers' 카테고리의 다른 글
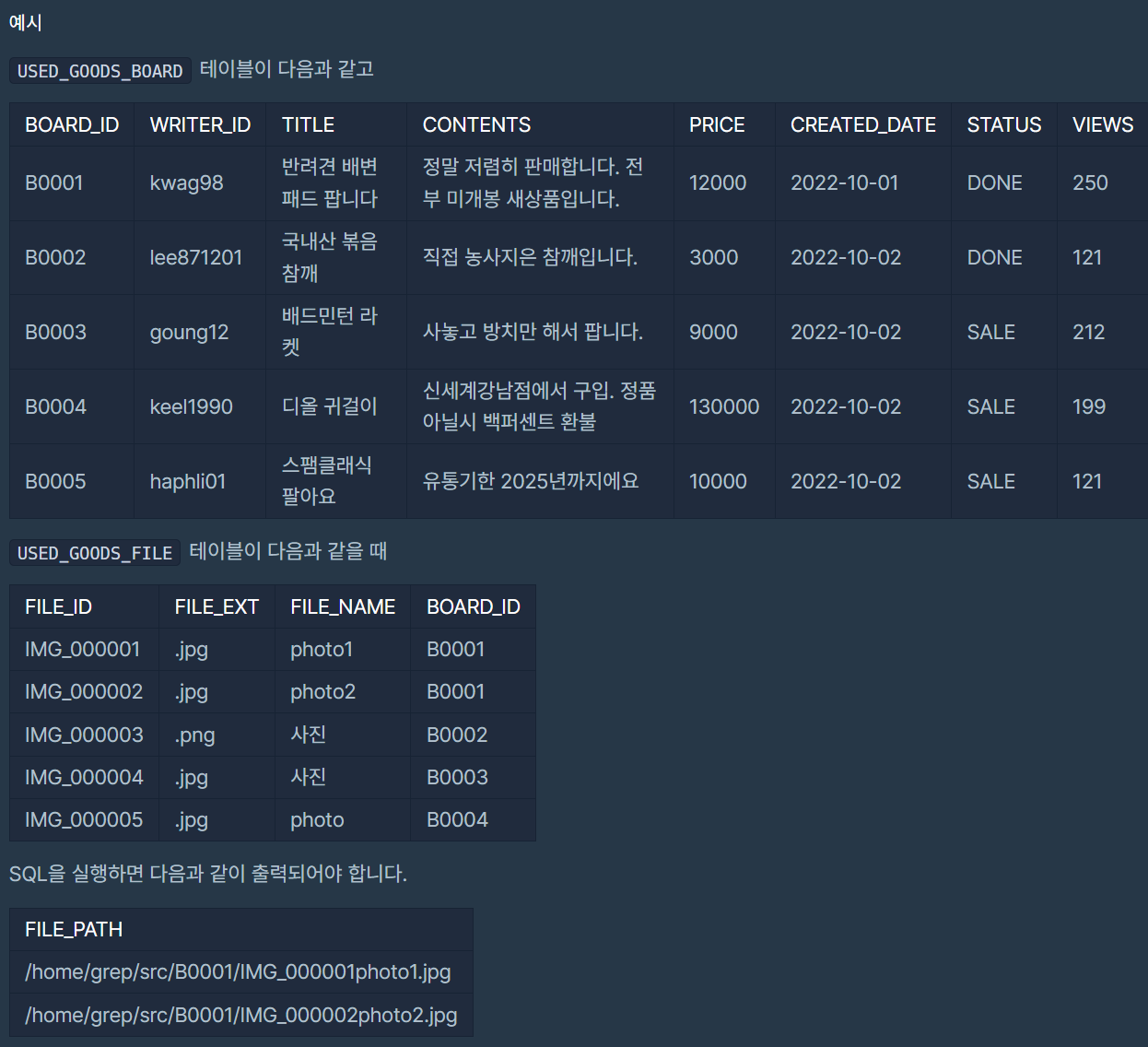
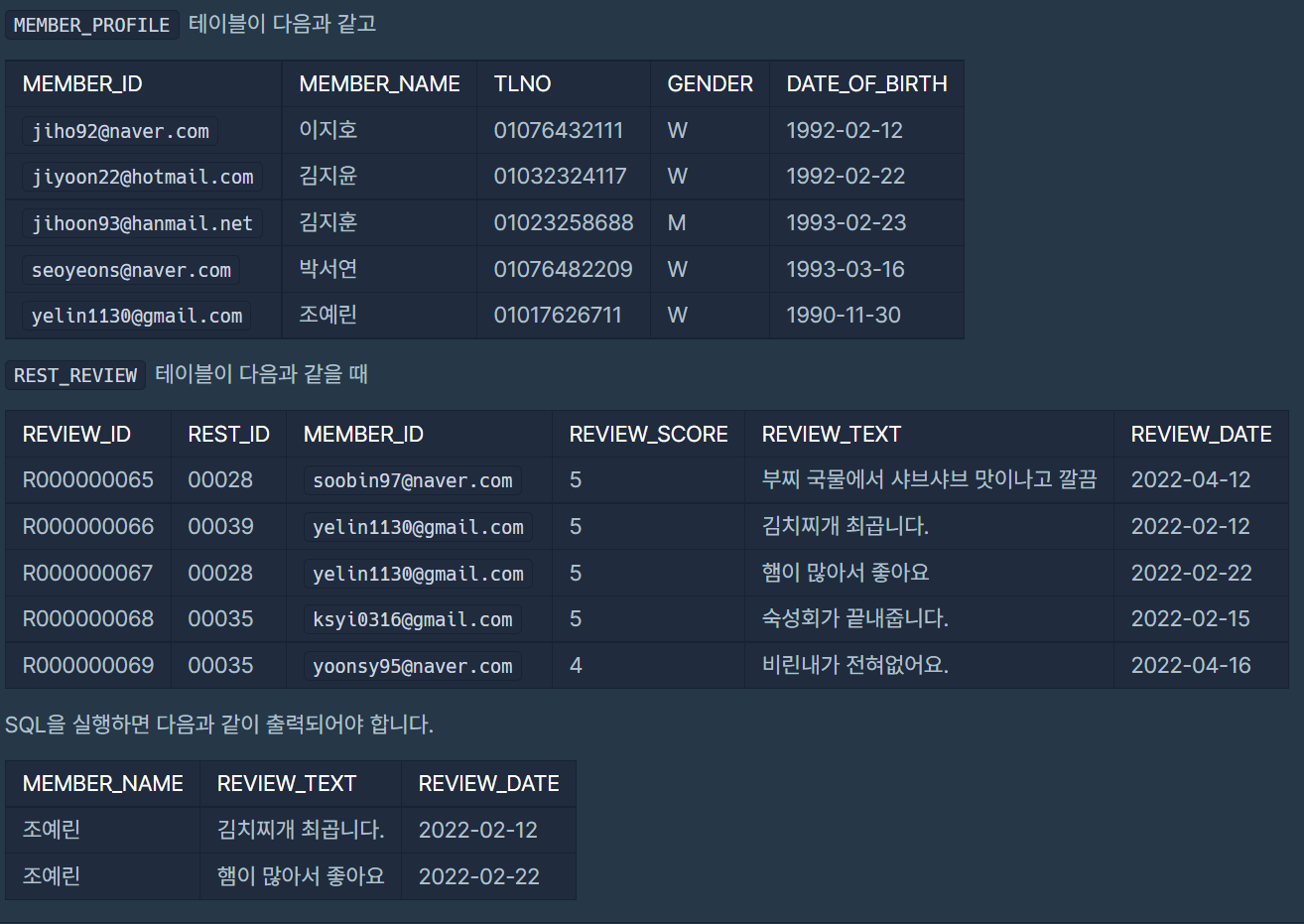
| 프로그래머스 (Level 3) : 조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기/ (SQL) Oracle/ WITH, JOIN (0) | 2023.04.25 |
|---|---|
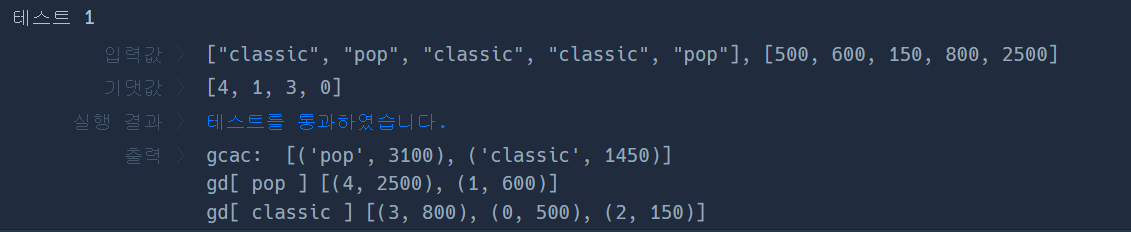
| 프로그래머스 (Level 3) : 베스트앨범/ python, 리스트 딕셔너리, 해쉬 (2) | 2022.10.13 |
| 프로그래머스 (Level 2) : 구명보트/ C++, Python, Greedy (2) | 2022.10.11 |
| 프로그래머스 (Level 3) : 정수 삼각형/ C++, DP/ vector 최대값 *max_element, greater<>() (4) | 2022.10.11 |
| 프로그래머스 (Level 4) : 그룹별 조건에 맞는 식당 목록 출력하기/ (SQL) MySQL, Oracle/ JOIN, RANK() (0) | 2022.10.10 |